A TCP feladata, megbízhatatlan (best-effort) hálózatok összekapcsolása esetén a két végpontban működő programok között megbízható, sorrendhelyes full duplex bytefolyamot biztosítson. Ebből következik, hogy a TCP két alkalmazást között logikai összeköttetést hoz létre. (Emlékeztetőül: az IP két host között hoz létre logikai összeköttetést, míg az Ethernet két szomszédos hálózati eszköz között fizikai összeköttetést létesít.) A TCP mindig két végpont közötti összeköttetést jelent, pont-többpont összeköttetést TCP-vel megvalósítani nem tudunk. Tipikus példa a webböngésző és a webszerver kapcsolata. A két végpontot azok IP-száma, míg a rajtuk futó, egymással kommunikálni kívánó alkalmazásokat a portszámok (amelyekkel tulajdonképpen interfészket jelölünk meg) azonosítják. Ez az azonosítás globálisan egyedi. Érdemes megjegyezni, hogy (i) ez az azonosító változhat az átviteli út különböző részein (lásd: NAT), illetve (ii) az azonosító egyes elemei különböző rétegekben használatosak.
A TCP menedzsmentfunkcióit tekintve befolyással van a szegmensméretre, forgalomszabályozást és torlódásvezérlést végez. Fontos látnunk, hogy ezek miatt a TCP az általa összekapcsolt alkalmazásoktól "függetlenített" adatírási és adatküldési ütemezéssel/időzítéssel/sebességgel rendelkezik. Emiatt a TCP bizonyos alkalmazások esetén nem használható megfelelően, ilyenek például a valósidejű összeköttetések.
Technikai szempontból a TCP az operációs rendszerek által vezérelt ún. socket-ek között teremt kapcsolatot, amelyek az alkalmazás szempontjából interfésznek tekinthetőek. A socketre a portszámmal hivatkozunk (lásd alább a TCP fejléc szerkezetét). A TCP protokoll működése 3 részre bontható: (i) az összeköttetés létrehozása, (ii) adatátvitel, (iii) az összeköttetés lebontása.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forrásport | Célport |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sorszám |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Nyugta sorszáma |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| TCP | Fenn- |U|A|P|R|S|F| |
|fejrész| tartott |R|C|S|S|Y|I| Ablak |
|hossza | |G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Ellenőrzőösszeg | Sürgősségi mutató |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Opciók (ha vannak) | Kitöltés |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Tényleges adatok |
.
.
.
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
A fejléc a fentiek szerint legalább 20 oktetből áll, az egyes elemeket bemutatjuk az alábbiakban:
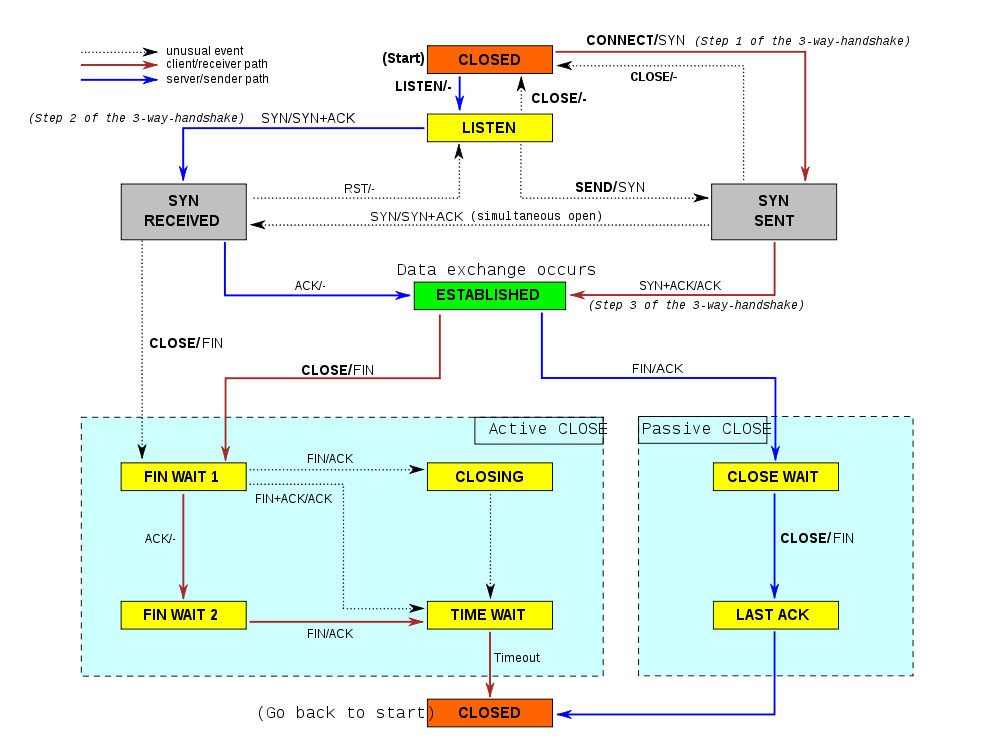
Minthogy a TCP összeköttetés orientált (connection oriented) hálózati rétegbeli protokoll, így mielőtt a TCP felhasználásával adatot szeretnénk átvinni két különböző számítógépen futó alkalmazás között, kapcsolatot kell felépítenünk. A TCP kapcsolatot kezdeményező felet kliensnek (client host) nevezzük, míg a másik felet kiszolgálónak (server host) hívjuk. A TCP kapcsolat létrehozását - amit gyakran hívnak angol terminológiával 3-way-handshake-nek - az alábbi ábra szemléleti:
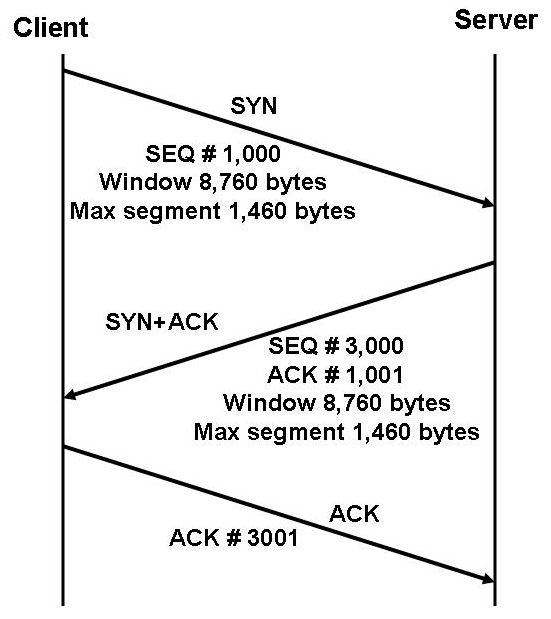
A ábráról leolvasható, hogy az egyes szegmensekben melyik flag-ek 1 értékűek, illetve megjelöltük a sorszámokat és a nyugták sorszámait, ahol ezek érdekesek lehetnek. A kezdeti sorszámokat (ISN - Initial sequence Number) véletlenszerűen választjuk. Ennek oka egy lehetséges támadás kivédése (bővebben lásd RFC 1948).
Az ábrán látható módon a kapcsolatfelépítéskor határozzuk meg a maximális szegmensméretet (Maximum segment Size - MSS), ami a TCP szegmensben található alkalmazási rétegbeli adat maximális mérete. Az MSS értéke függ a TCP implementációtól (amit meghatároz az operációs rendszer), de legtöbbször konfigurálható (amint az ábrán látható is) a megfelelő Opció fejlécelem használatával. Az aktuális értéket annak megfelelően szokták beállítani, hogy az IP fragmentációt elkerüljük. Az IP fragmentációra akkor kerül sor, ha az IP csomag mérete meghaladja az adatkapcsolati réteg által a PDU méretére engedélyezett maximumot (Maximum Transmission Unit - MTU). A fragmentációt lehetőség szerint el akarjuk kerülni, mivel újraküldés esetén extra forgalmat generál. Emiatt az MSS értéke igazodni szokott az MTU-hoz. A jelenlegi Interneten az IP általában Ethernet felett fut (pontosabban EthernetII keretekbe csomagoljuk az IP csomagokat), amelynek MTU-ja 1500 byte. Bizonyos eszközgyártók lehetővé teszik ún. Jumbo-frame-ek használatát, amelyek esetén az MTU 9000 byte is lehet, ez azonban csak LAN-okon fordulhat elő, border protokollok (pl. PPPoE) ezt redukálják a szokásos méretre. WLAN-on az MTU értéke 2272 byte. Minthogy a TCP két számítógépen futó alkalmazás között teremt összeköttetést, amelyek az Interneten tetszőleges helyen lehetnek, nem lehetünk biztosan abban, hogy az átviteli út során mindenűtt ugyanaz az MTU érvényes. Azért, hogy az útközbeni átcsomagolást elkerüljük, meg kell tudnunk az egész útvonalra érvényes MTU-t, ami nyilván a legkisebb MTU lesz. Az eljárást, amit az RFC 1191 (IPv4) illetve az RFC 1981 (IPv6) ír, le angol terminilógiával "Path MTU Discovery"-nek nevezzük és ICMP-t használ.
A jelenleg érvényes ajánlások szerint az implementációknak már kötelezően támogatniuk kell szelektív nyugtázást (SACK). Ebben az esetben az Opció mezőt vesszük igénybe és egy vagy több összefüggő sorszámtartományt tudnuk nyugtázni. Ez a megoldás az újraküldés hatékonyságát jelentősen javítja.
Az egyidőben nyugtázatlan adatmennyiséget tehát az "Ablak" hirdeti meg (Advertised Window). Ennek változtatásával a célpont egyértelműen a forrás tudtára adhatja, hogy mennyi adatot képes még fogadni, vagyis megakadályozza, hogy egy gyors küldő elárassza a vevőt (folyamvezérlés - flow control). Amikor a csomagok sorrendben, hibátlanul érkeznek, akkor az ablak mérete tulajdonképpen állandó (vagy csak kissé ingadozik a késleltetett nyugta miatt), ugyanakkor a kezdőpontja folyamatosan emelkedik ("csúszik" - innen az elnevezés). Erre az önszabályozó jellegre az angol termiológiában a "self clocking" kifejezéssel hivatkoznak. Ha nem sorrendhelyesen érkeznek a csomagok, akkor a nyugta sorszáma (vagyis az ablak kezdőpontja) változatlan, ugyanakkor a mérete csökken, hiszen a sorrenden kívül érkezett csomagokat eltároljuk (amennyiben az ablakon belülre esnek, egyébként eldobjuk). Ugyancsak eldobjuk a duplikált csomagokat. Ilyen módon, a csúszó ablakkal ellátott vevőpuffer szolgál a szegmensek sorrendjének helyreállítására. Az adatfolyam elveszett részeinek helye üresen marad az ablakban, a nyugtákkal jelezzük a hiányt és a pótlólag megérkező szegmensekről kumulatív nyugtát küldünk, így lesz az adatátvitel megbízható. A csúszó ablak (Sliding Window) használatát könnyen megérthetjük az alábbi ábrából és képletekből.
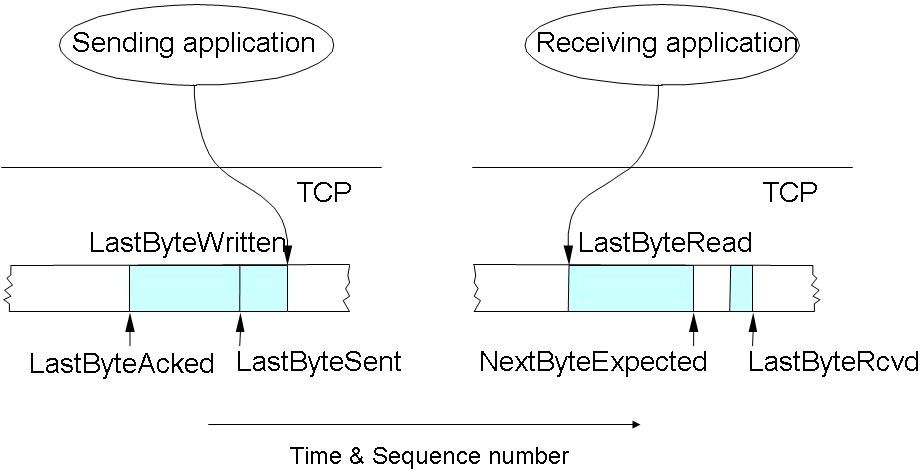
A megbízható és sorrendhelyes adatátvitel feltételei:
A folyamvezérlés megvalósításának szabályai
Mivel a TCP megbízható átvitelt nyújt, minden olyan szegmenst újraküldünk, amire egy meghatározott időn belül nem érkezik nyugta. Minden szegmenshez egy újraküldési időzítőt kapcsolunk, amely az RTO (Retransmission Timeout) lejárta után újraküldi a szegmenst. Az RTO-t a kommunikáció két végpontja közötti kétirányú késleltetés (RTT - Round Trip Time) alapján határozzuk meg, azonban az Internet két tetszőlegesen kiválasztott végpontja között az több nagyságrendet átfogó tartományba eshet az RTT, sőt két kiválasztott host között időben is jelentős ingadozást mutathat a késleltetés alakulása, vagyis az RTT meghatározása meglehetősen nehéz feladat lehet, aminek megoldására az idők folyamán egyre jobb javaslatok születtek:
Az eredeti algoritmus szerint minden szegmens/nyugta pár esetén mértük az aktuális körbefordulási időt (SampleRTT) amelyekből egy súlyozott összeget számítottunk:
EstimatedRTT = a*EstimatedRTT + b*SampleRTT,
ahol a+b = 1 és a értéke 0.8 és 0.9, míg b értéke 0.1 és 0.2 között van.
Az időzítőt (RTO) az EstimatedRTT alapján a következőre választjuk:
TimeOut = 2 * EstimatedRTT
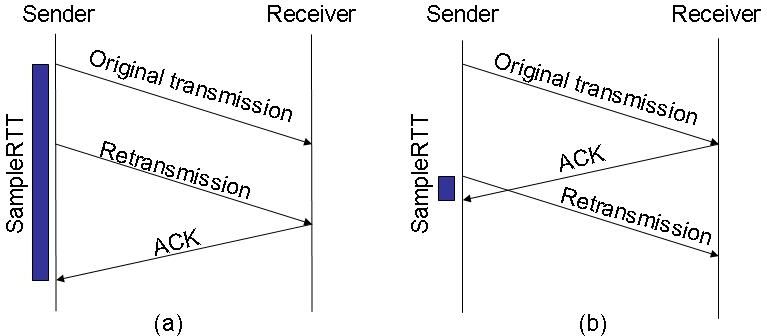
A Karn/Partridge algoritmus módosította az eredeti, mivel felismerték, hogy az újraküldött csomagok esetén a SampleRTT nem valós infromációt hordoz (lásd az alábbi ábrát), ezért az újraküldött csomagokat nem szabad figyelembe venni az RTT becslésénél. Ugyanakkor ez önmagában további problémát generál, hiszen ha feltételezünk egy olyan helyzetet, ahol az átviteli késleltetés nagyon hirtelen (két szegmens között) jelentősen megnövekszik, akkor a fenti szabály oda vezetne minket, hogy az RTT-t többé nem frissítenénk. Ezért alkalmazzuk az "exponenciális kihátrálást" (exponential backof), ami azt jelenti, hogy minden újraküldés esetén az RTO-t kétszeresére növeljük:
new_TimeOut = old_TimeOut*2.
Ez az eljárás a gyakorlatban biztosítja a hálózat stabilitását.
A Jacobson/Karels algoritmus Van Jacobson 1988-as cikkében jelent meg először. A cikk tulajdonképpen több algoritmust tárgyal, amely később RFC-kben közzétéve hivatalos szabvánnyá váltak. Az algoritmusok - bár különböző területeket érintettek - valamennyien az Internet 1986 októberétől kezdődő sorozatos összeomlásaira kínáltak megoldást. Az összeomlások oka a torlódás volt (congestion collapse - (C) John Nagle), mivel annak kezelésére a korábbi szabványok nem készültek fel megfelelően. (Példaként leírhatjuk, hogy az RTT becslésére szolgáló eredeti algoritmus nagyjából 30%-os terhelésig működött.)
A torlódás nem csak az átbocsátóképességet csökkenti - Jacobson példája: 32 kbps-ról 40 bps-ra csökkenő sávszélesség két, egymástól 400 yardra levő számítógép között, amelyek között 3 IMP hop (Interface Message Processor - az ARPAnet hálózati eleme) található -, hanem a végül megérkező csomagok késleltetésének a szórását is jelentősen megnöveli. Az pedig könnyen belátható, hogy ha az RTT szórása nagy, akkor az RTO-nak jóval nagyobbnak kellene lennie az RTT átlagánál. Így a következő szabályokat használjuk:
Difference = SampleRTT - EstimatedRTT
EstimatedRTT = EstimatedRTT + ( d * Difference)
Deviation = Deviation + d ( |Difference| - Deviation)), ahol d egy 0 és 1 közötti tört.
Az RTO beállításánál vegyük figyelembe a szórást:
Timeout = u * EstimatedRTT + q * Deviation, ahol u = 1 és q = 4 .
A TCP torlódáskezelése (TCP Congestion Control)
A torlódás, mint ezt korábban írtuk, nem az Internet kezdeti jelenségei közé tartozik, hanem csak a '80-as évek második felétől tapasztalták meg egyre nagyobb méretekben. A megoldási javaslatokat Jacobson a már említett cikkében publikálta. A TCP torlódáskezelés négy, egymáshoz kapcsolódó algoritmusból áll, amelyeket szabványként az RFC 2581 írt le, jelenleg ebben a tárgyban az RFC 5681 érvényes. Az algoritmusokban megjelenik két új változó. Az egyik "congestion window" (torlódási ablak) néven, amelyet többnyire a "cwnd" (vagy a "CongWin") rövidítéssel jelölünk és ezentúl a küldő ablakaként a vevő meghirdetett ablaka és a torlódási ablak közül a kisebbet kell figyelembe vennünk. A másik változó a "slow start threshold" (ssthresh - lassú indítási küszöb), amely két algoritmus közötti váltásnak a határpontja. További fontos újdonság, hogy a csomagvesztést a torlódás jelének tartjuk és a csomagvesztésre különbözőképpen regálunk aszerint, hogy az időzítő lejárta alapján észleljük azt vagy 3 duplikált nyugta alapján tekintjük a csomagot elveszettnek.
A négy eljárás a következő:
A TCP torlódáskezelése felfogható egy állapotgépként is. Az alábbi táblázat tájékozat arról, hogy az egyes állapotok között milyen átjárás lehetséges.
| állapot | Esemény | TCP küldő tevékenysége | Megjegyzés |
|---|---|---|---|
| Slow Start (SS) | ACK érkezik korábban nem nyugtázott adatra | CongWin = CongWin + MSS, Ha (CongWin > Threshold), akkor "Congestion Avoidance" állapotba lépünk át. | CongWin duplázódik minden RTT alatt. |
| Congestion Avoidance (CA) | ACK érkezik korábban nem nyugtázott adatra | CongWin = CongWin+MSS * (MSS/CongWin) | Additive Increase, a CongWin 1 MSS-sel nő minden RTT alatt |
| SS vagy CA | Csomagvesztést észlelünk: 3 duplikált ACK érkezett | Threshold = CongWin/2, CongWin = Threshold, "Congestion Avoidance" állapotba lépünk | Fast recovery, Multiplicative Decrease. A CongWin nem eshet 1 MSS alá. |
| SS vagy CA | TimeOut | Threshold = CongWin/2, CongWin = 1 MSS, "Slow Start" állapotba lépünk. | A lassú indulás fázis kezdődik. |
| SS vagy CA | Duplikált ACK érkezik | Növeljük a nyugtázott csomag duplikált ACK számlálóját | A CongWin és a Threshold változatlanok |
Érdemes tudni, hogy az IP hálózatokon előforduló torlódás kezelésére egyéb, nem a TCP-ben megvalósított lehetőségeink is vannak, amelyek azonban valamilyen módon mégiscsak kapcsolódnak hozzá. Ilyen lehetőségek például a RED (Random Early Detection) vagy az ECN (Explicit Congestion Notification), amely utóbbival kapcsolatban a két új TCP jelzőbitet már említettük.
A TCP igazságossága (fairness)
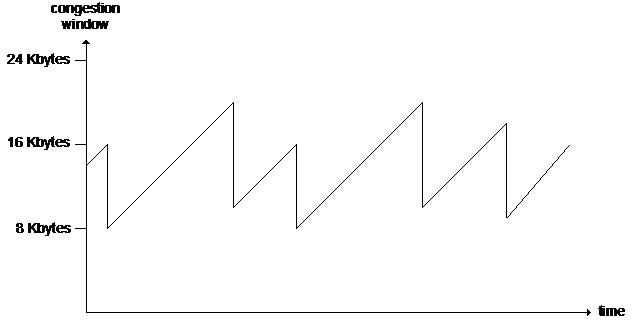
Ha egy szűk linken több TCP folyam is osztozik, akkor elvárhatjuk, hogy azok a kezdeti paramétereiktől függetlenül igazságosan osztozhassanak az erőforrásokon. Ezt a torlódás elkerülésnél használatos Additive Increase/Multiplicative Decrease sebességszabályozás biztosítja, amint ez az alábbi ábráról megérthető.

Ennek eredményeképpen alakul ki a TCP közismertnek mondható fűrészfog alakú sebességgörbéje, ami alapján a TCP átlagsebességére vonatkozólag is egy egyszerű becslést tehetünk: 0.75*cwnd/RTT. Természetesen a becslés akkor igaz, ha a torlódási ablak korlátozza az átvitelt és az átviendő byte-folyam elég hosszú ahhoz, hogy a lassú indulás fázis hossza elhanyagolható legyen a torlódás elkerülés fáziséhoz képest. Az fűrészfog görbe nem csak a sebességet jellemzi, hanem alakja megfeleltethető a cwnd méretének illetve a vevőpufferben található adatmennyiségnek is.
Látnunk kell azt, hogy a TCP menedzsmentfuncióinak a célja az, hogy a rendelkezésre álló átviteli kapacitást kihasználva a lehető legnagyobb hatékonyságot (throughput-ot) érjünk el, vagyis a linket a lehető leginkább telítetnünk kell. Az eddigi tárgyalt részleteken túl még szót kell ejtenünk az Ablak és a Sorszámról, vagyis arról, hogy ezek használata miként befolyásolja a fenti cél elérhetőségét.
Az Ablakról elmondtuk, hogy a vevő tud ebben a fejlécelemben a küldőnek üzenni, és megadhatja benne az általa még fogadható byte-ok számát (Advertised Window), amely maximum 64kB lehet, hiszen az Ablak mező 16 bites. Ennek a méretnek és a torlódási ablaknak a minimuma adja meg a küldő számára, hogy mennyi nyugtázatlan adatot küldhet el összesen. Tegyük fel, hogy a vevő megfelelő teljesítményű és a hálózat terheletlen, az RTT pedig 50 msec. Egyszerűen megmutatható, hogy a forrás csak akkor tudja telíteni a linket, ha az AW maximuma nagyobb lehet, mint az ún. "sávszélesség-késleltetés szorzat" (Bandwitdh-Delay Product - BDP) értéke. Az alábbi táblázat néhány lehetséges sávszélesség értékére vonatkoztatva megadja a BDP-t.
| Bandwidth [Mbps] | BDP (RTT=50 msec) [kB] | Átfordulási idő |
|---|---|---|
| T1 (1.5 Mbps) | 9 | 6.4 óra |
| ADSL (5 Mbps) | 31 | 1.9 óra |
| Ethernet (10 Mbps) | 61 | 57 perc |
| T3 (45 Mbps) | 275 | 13 perc |
| Fast Ethernet (100 Mbps) | 610 | 5.7 perc |
| STS-3 (155 Mbps) | 946 | 3.7 perc |
| STS-12 (622 Mbps) | 3796 | 55.2 másodperc |
| Gigabit Ethernet (1000 Mbps) | 6104 | 34.4 másodperc |
Látható, hogy a 10 Mbps-os vonal még betölthető a 64 kB-os Ablakkal, nagyobb sebességű link azonban már nem. A probléma megoldására a TCP fejléc opciói közül a Window Scale (RFC 1323) használatos: itt egy 8 bites mező áll a rendelkezésünkre, amelynek értéke azt adja meg, hogy hány bittel toljuk el (shift) el a vett értéket balra (illetve a küldendő értéket jobbra). Az így nyert lehetőségeket azonban nem használhatjuk ki teljes mértékben: maximálisan 14 lehet a window scale factor értéke, ami nagyjából 1 GB-os ablakértéknek felel meg.
A Sorszám egy 32 bites átforduló szám, amelynek a kezdeti, véletlenszerűen választott sorszámértékhez képesti eltolása megegyezik az adott szegmens első adatbyte-jának az átviendő byte-folyamban elfoglalt pozíciójával. A vett szegmens sorszáma alapján dönt a vevő arról, hogy ez beleillik-e a vételi ablakába vagy el kell-e dobnia. A 32 bittel nagyjából 4 GB adat címezhető meg, ami manapság nem számít nagyon soknak. A fenti táblázat 3. oszlopában az adott sávszélességű linken mért átfordulási időt (az az idő, ami alatt a teljes sorszámkészletet elhasználjuk - time to wrap around) tüntettük fel. Ezen kívül még arra is figyelnünk kell, hogy a küldő és a vevő ablaka nem pontosan fedi egymást, így némi számolgatás után arra juthatunk, hogy a SenderWindowSize < (MaxSeqNum +1)/2 feltétel betartása szükséges. Látható, hogy nagyobb sebességű hálózatokon ez már viszonylag rövid idő alatt bekövetkezik. A megoldási lehetőséget erre a problémára megint a TCP opciók között kereshetünk. Az RFC 1323-ben leírt Timestamp (Időbélyeg) opció használatával lehetőségünk van arra, hogy akár nagy ablakméret mellett is megkülönböztessünk azonos sorszámmal érkező szegmenseket. Fontos tudnunk, hogy az időbélyeg időegységeket számol, a számlálót a SYN-SYN/ACK üzenetváltás során tudjuk inicializálni és szinkronizálni. Az időalap megválasztásával kacsolatban a szabvány szerint 1 msec és 1 sec közötti értéket kell használni, a gyakorlatban néhányszor 10 és néhányszor 100 msec közötti időalapot szoktak választani. Ez az Időbélyeg opció másik célra való használatára megfelelő, ugyanis arra is lehetőségünk van az időbélyeg visszaküldésével, hogy az RTT-t viszonylag pontosan mérni tudjuk. A mérés eredményét mind az RTO számítására, mind a torlódás előrejelzésére használhatjuk.
A TCP sorszámokat az idő függvényében ábrázolva szemléletes képet kapunk az adott TCP folyam jellegzetességeiről. A léptékhelyes diagramon nemcsak a torlódáskezelés egyes lépései követhetőek nyomon, hanem a TCP összeköttetésre vonatkozó jellemző mennyiségeket is le tudjuk olvasni (például: MSS, RTT-k, RTO, ablakméretek, stb.).

A TCP adatfolyam utolsó byte-jának átvitele után az összeköttetést le kell zárnunk. A lezárás a két fél által kölcsönösen elküldött FIN jelzőbites szegmensekből és az arra adott nyugtákból áll, vagyis alapvetően 4 üzenetet használunk, ami nem is meglepő, ha arra gondolunk, hogy a TCP full-duplex összeköttetést nyújt. Egy lehetséges esetet mutat be az alábbi ábra. Érdemes megjegyezni, hogy az állapotgráfban nem azonnal a második nyugta után kerülünk CLOSED állapotba, hanem még ki kell várni egy időzítő lejártát.

Az ábráról leolvasható, hogy előfordulhat olyan eset, amikor az egyik fél már lezárta az összeköttetést, míg az a másik oldalról nyitva marad (half open). Lehetséges az is, hogy a két fél kölcsönösen le akarja zárni az összeköttetést, vagyis a FIN szegmenst mindketten úgy küldik el, hogy a másiktól még nem kaptak ilyent. Végül meg kell említenünk, hogy a mai implementációkban gyakran használják a TWH megfelelő változatát, vagyis az aktív FIN-re adott nyugta és a passzív FIN egy szegmensben megy.
A hálózati sávszélesség folyamatos növekedése felvetette a link telíthetőségének a problémáját, amiről már korábban szó esett illetve azt a problémát, hogy a visszacsatolás ideje (vagyis az RTT) kisebb állományok esetén összemérhető a teljes állomány átviteléhez szükséges idővel, azonban a slow start miatt ez utóbbi jelentősen hosszabb lesz a szükségesnél. Ennek két következménye, hogy a torlódásvezérlés és a forgalomszabályozás nem lesz hatékony, illetve a link kihasználtsága kicsi lesz. E fentiekben már bemutattunk néhány lehetőséget, amelyekkel a nagy sebességű hálózatok nyújtotta átviteli lehetőségeket jobban ki tuydjuk használni, azonban sokak szerint a TCP javítgatása helyett új algoritmusokra lenne szükség. Az ún. nagysebességű TCP-változatok közül néhány ismertebbet az alábbi táblázatban foglaltunk össze.
| A protokoll neve | Típus | Kik, mikor javasolták | Főbb jellemzők |
|---|---|---|---|
| HighSpeed TCP | csomagvesztés alapú | S. Floyd, International Computer Science Institute (ICSI), Berkeley University of California, 2003. | AIMD |
| Scalable TCP | csomagvesztés alapú | T. Kelly, CERN & University of Cambridge, 2003. | MIMD |
| BIC TCP / CUBIC | csomagvesztés alapú | I. Rhee et al., Networking Research Lab, North Carolina State University, 2004. és 2005. | jó kihasználtság, fairness és stabilitási tulajdonságok |
| FAST TCP | késleltetés alapú | S. Low et al., Netlab, California Institute of Technology, 2004. (ma: FastSoft Inc.) | bíztató fairness tulajdonságok |
| TCP Westwood | mérés alapú | M. Y. Sanadidi, M. Gerla et al., High Performance Internet Lab, Network Research Lab, University of California, Los Angeles (UCLA), 2001 és 2005 között | több változat, különböző becslési módszerek |
| Compound TCP | hibrid | K. Tan et al., Microsoft Research, 2005. | AIMD + késleltetés alapú komponens |
| XCP | explicit torlódásjelzés | D. Katabi et al., Massachusetts Institute of Technology (MIT), 2002. | routerek módosítása szükséges |
Az UDP felhasználói datagram protokoll. Lehetővé teszi a felhasználóknak, hogy összeköttetés felépítése és lebontása nélkül üzenetet küldhessenek. Nem garantálja sem az üzenetek kézbesítését, sem azok sorrendtartását.
bytes (20) from IPv4 keret
+--------------------------------+
2 | Source Port |
+--------------------------------+
2 | Destination Port | Pl: 5004 (avt-profile-1) RTP media data
+--------------------------------+
2 | Length (8 byte header + max. |
| 65527 byte data) |
+--------------------------------+
2 | Checksum (header+data) |
+--------------------------------+
0000 70 cd 70 64 08 00 45 b8 ..)../.`p.pd..E.
0010 00 c8 9e 11 00 00 3e 11 c1 48 98 42 f5 ab 98 42 ......>..H.B...B
0020 f5 e2 46 b0 13 8c 00 b4 00 00 80 00 3d 7c 00 28 ..F.........=|.(
0030 0c 40 d4 7b 28 21 f9 f7 fc ff 7b 7d fd 7c 7c 78 .@.{(!....{}.||x
0040 7a fc 7c 7a 7f fd fd 7e ff fd fb f8 f3 f0 f3 f7 z.|z...~........
0050 fc fb f8 fa 7d 76 78 79 77 77 78 7a 7b 7b 7c 7d ....}vxywwxz{{|}
0060 7e fe fe fd f9 f7 fb fc f7 f9 fb fb fc fa fa fd ~...............
0070 fd fb fb fa fd fe fd fc f8 fa fd fb fc fd fb fa ................
0080 f8 f8 fe fe fa fa fb fd 7e 7b 79 78 79 7f fa fe ........~{yxy...
0090 7c 7f 7e 7c 7e 7f 7b 7b 7c 7a 78 78 78 74 75 79 |.~|~.{{|zxxxtuy
00a0 7c 7c 7c 7f fc f9 fa fc fa f9 f9 fc 7d 7e fb f9 |||.........}~..
00b0 f7 f9 7f 7e fe fd fb fb fc fe 7d fc f9 fe 7e 7b ...~......}...~{
00c0 7c 7b 7b 7a 79 7b 7a 7c 7c 79 7c 7a 79 7b 7c 7b |{{zy{z||y|zy{|{
00d0 7b 7b 7b 7c 7b 7b {{{|{{